本期要点:
异步刷新
之前爬取p站,我们遇到一个问题,就是p站排行榜是异步刷新的,一次刷新50张。
但是我们知道,p站异步刷新通过json实现,每次下拉到一定地方就会接受到一个json文件,里面含有下一个50张图片的内容
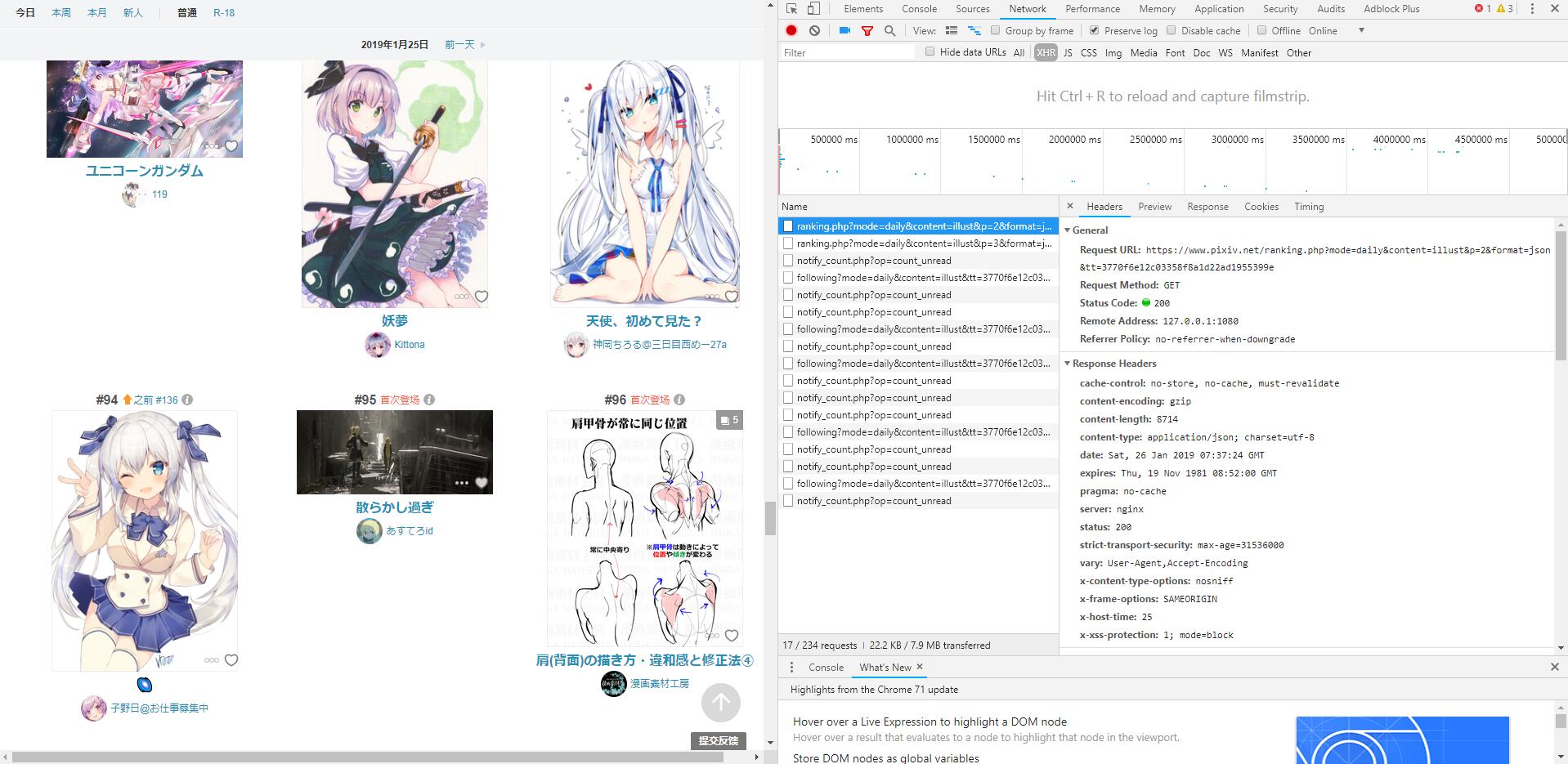
根据观察,我们发现,request url都差不多,’p’这个参数,决定是第几页,’tt’这个参数我推断可能是个人的cookie,每天都是这个不会随时间改变
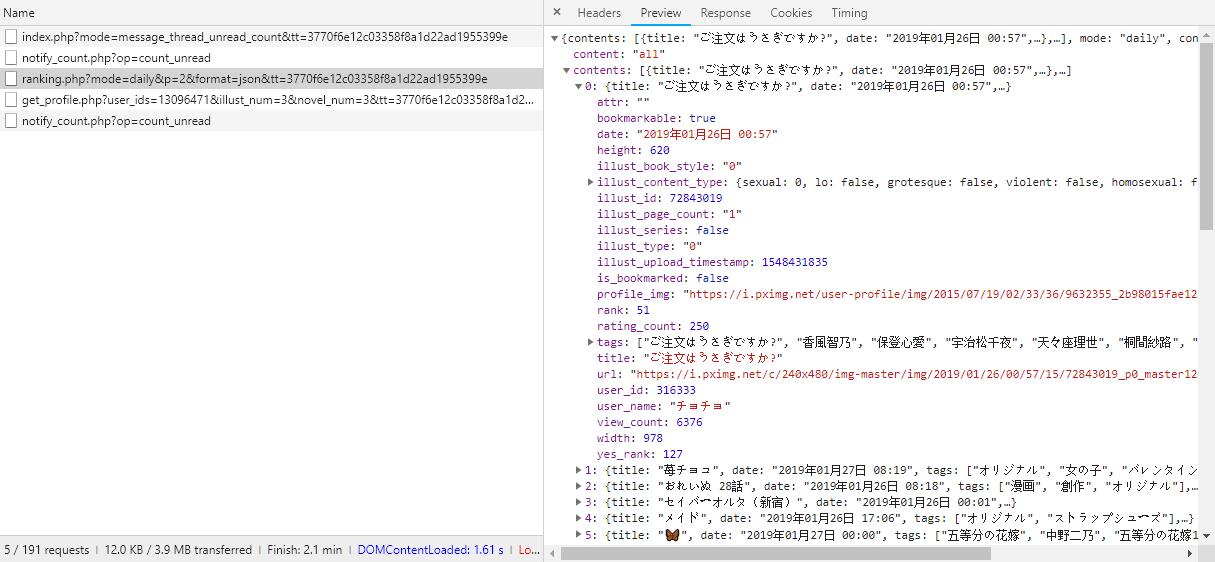
而这个json的内容里面就包含了每张图片的信息 我们直接爬取出来id就好
1
2
3
4
5
6
7
8
| import json
import requests
web = 'https://www.pixiv.net/ranking.php?mode=daily'
urls = 'https://www.pixiv.net/ranking.php?mode=daily&p=2&format=json&tt=3770f6e12c03358f8a1d22ad1955399e'
webhtml = requests.get(urls)
data = json.loads(webhtml.text)
urls = data['contents'][10]['url']
print(urls)
|
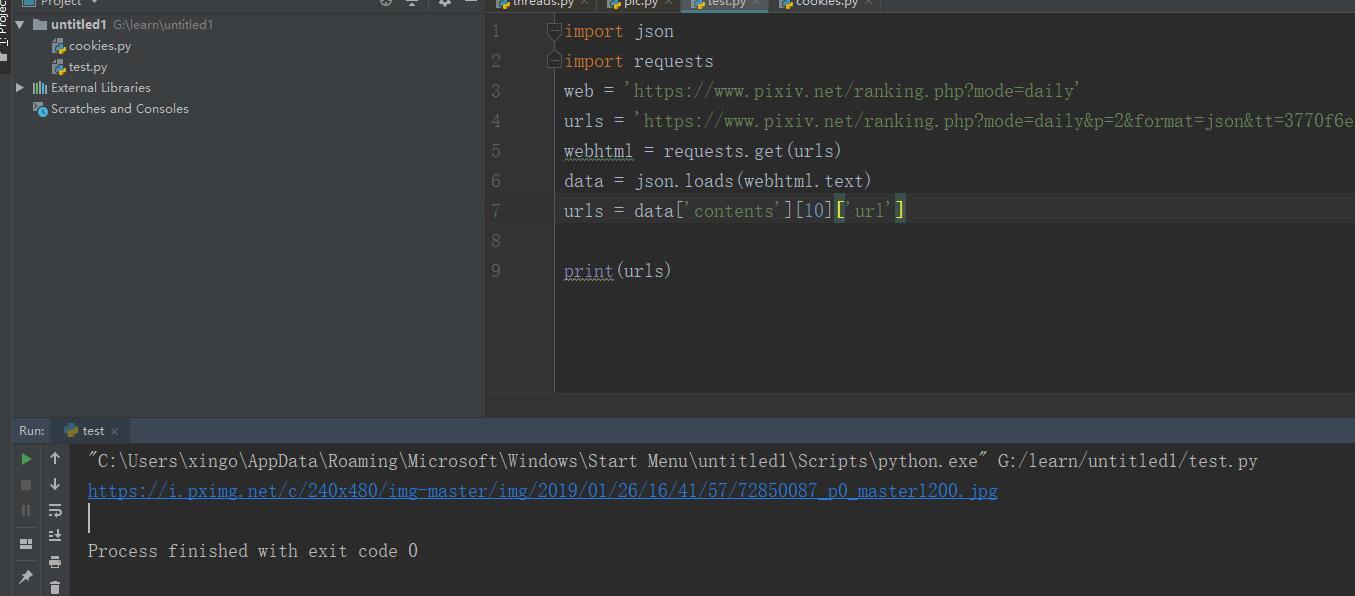
这样子就爬取到了id,利用循环就可以得到多个id,用到先前的下载方法就可以批量爬取相关内容了。
这里一定要注意,每次爬取都要设置一点暂停时间,不然容易被识别为爬虫程序,被禁止。
cookies
requests.Session()的使用,使requests维持一个会话对象,能自动处理服务器发来的cookie,使得同一个会话中的请求都带上最新的cookie,非常适合模拟登录。
如果去掉了会发生什么你们可以在以下的代码中尝试一样
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
import requests
import http.cookiejar as cj
import urllib3
import re
s = requests.Session()
return_to = 'https://www.pixiv.net/'
pixiv_id = 'xxxxx'
password = 'xxxxx'
post_key = []
baseurl = 'https://accounts.pixiv.net/login?lang=zh&source=pc&view_type=page&ref=wwwtop_accounts_index'
Loginurl = 'https://accounts.pixiv.net/api/login?lang=zh'
pixiv_id = input('pixiv_account:')
password = input('password:')
loginHtml = s.get(baseurl)
pattern = re.compile('<input type="hidden".*?value="(.*?)">', re.S)
result = re.search(pattern,loginHtml.text)
post_key = result.group(1)
logindate = {
'pixiv_id': pixiv_id,
'password': password,
'post_key': post_key,
'return_to': return_to
}
loginheader = {
'Host': 'accounts.pixiv.net',
'User_Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
'Referer': 'https://accounts.pixiv.net/login?lang=zh&source=pc&view_type=page&ref=wwwtop_accounts_index',
'content-type': 'application/x-www-form-urlencoded',
'Connection': 'keep-alive'
}
re = s.post(Loginurl,data = logindate, headers = loginheader)
pagehtml = s.get('https://www.pixiv.net/setting_user.php')
print(pagehtml.text)
|
使用本机代理
之前爬取p站的东西一直开着全局代理很不方便,后来找了个办法
1
2
3
4
| import requests
proxies = {"http": "127.0.0.1:1080", "https": "127.0.0.1:1080"}
m = requests.get('https://youtube.com', proxies=proxies)
print (m)
|
这样子就能用本机的酸酸乳了
多线程
单线程往往会遇到一个问题,如果爬取过程出错,那么整个爬取的过程就会停下来,因此要避免这个问题。
利用线程优先队列来解决这个问题,将下载的地址放入queue中,创建多个线程同步处理。
现在我们整合json内容,以及上一章的内容,利用多线程爬取每日排行榜的至少100张图片。
之后的内容章节
(摸了)
- 自动化代理池
- selenium
- PhantomJS
- 验证码
- 机器学习